Introduction to Prompt Engineering
How to get your LLM to do what you want
2026-02-01
Overview
- Introduction to Prompting
- Best techniques for prompting
Overview
- Introduction to Prompting
- Best techniques for prompting
Introduction to prompting
Introduction to prompting
- Prompts are a natural (language) way to interact with language models
- very easy to understand
- anybody can do it
- it makes the interaction feel human
- Enables Semantic coding instead of logical coding
- This makes it very easy and very fast to iterate
NLP-lifecycle on it’s head
Regular ML:
Problem → Idea → Gather data → Train Model → Evaluate Model →
Repeat if neccessary → deploy
Duration: Months
Prompting workflow:
Problem → Idea → Gather (less) data → Finetune prompt → Evaluate Model →
Repeat if neccessary → already deployed
Duration: Days
Overview
- Introduction to Prompting
- Best techniques for prompting
Overview
- Introduction to Prompting
- Best techniques for prompting
Best techniques for prompting
Best techniques for prompting
- Make use of a general prompting template such as RTF
- Be precise in your description
- include a reference text
- ‘No’ is also an answer
- Give LLMs room to think
- Guide complex problems with chain-of-thought prompting
- Mind the Context Window!
General prompting template - RTF framework
- A general decent prompt templates looks like the following:
- Specify which ROLE the model should assume.
- Specify the TASK it should perform:
- TASK_DESCRIPTION: What is the task.
- TASK_SPECIFICATION: Specify how the task should be performed
- (Optional) Specify in what FORMAT the answer should be given.
General prompting template
- A general decent prompt templates looks like the following:
- Specify which ROLE the model should assume.
- Specify the TASK it should perform:
- TASK_DESCRIPTION: What is the task.
- TASK_SPECIFICATION: Specify how the task should be performed
- (Optional) Specify in what FORMAT the answer should be given.
Be precise in your task descriptions
You may think your task is clear, but it may not be:
As I’m going to the store, my roommate asks me: ‘Can you get a gallon of milk? And if they have eggs, get 6.’
When I come home my roommate was in shock: “You got 6 gallons of milk?!” I responded ‘They had eggs.’
Be precise in your task descriptions
- LLMs don’t know anything about you or the task it is given.
- Give the model the context it needs to know
- “Please explain to me how LLMs works?”
- What is your background knowledge? Academic, high-school, etc..
- How would you like the explanation? Technical, simple summary, funny, etc..
- How long should it be? 5 sentences, 5 paragraphs, 5 pages etc..
- Do you want the model to answer with or without the mathemathical foundations?
- Do you need references?
- etc…
Include a reference text
- LLMs should not be trusted with giving specific information, they can make up completely nonsence answers
- These answers are called Hallucinations, more on them later.
Include a reference text
- To help mitigate this (partially), you can Include a reference text1
- Note: Finding these reference texts in a smart way, is essentially what RAG systems do
f"""
ROLE: {ROLE}
TASK: {TASK_DESCRIPTION}
Your task is to answer the question using only the provided document
and to cite the passage(s) of the document used to answer the question.
The answer must be annotated with a citation.
Use the following format to cite relevant passages ({'citation' : …}).
{FORMAT_OUTPUT}
DOCUMENT:
'''
{DOCUMENT}
'''
"""Use delimiters
- Indicates what describes the task at hand, and what the task should be performed on
- use either:
- ### TEXT ###
- ““” TEXT “““
- ’’’ TEXT ’’’
- These triplets are all a single token
- Or use clear section titles, HTML-tags, etc.
‘No’ is also an answer!
- To help mitigate this (partially), you can Include a reference text1
- Explicitly tell the model to not answer the question if it can’t.
f"""
ROLE: {ROLE}
TASK: {TASK_DESCRIPTION}
Your task is to answer the question using only the provided document
and to cite the passage(s) of the document used to answer the question.
If the document does not contain the information needed to answer this question
then simply write:
'Insufficient information.'
If an answer to the question is provided, it must be annotated with a citation.
Use the following format to cite relevant passages ({'citation' : …}).
{FORMAT_OUTPUT}
DOCUMENT:
'''
{DOCUMENT}
'''
"""Give models time-to-think
- Allow the model to work through a problem first
- break up a task into smaller steps
f"""
Determine if my answer below is correct.
I'm trying to figure out how expensive my prompting of the GPT4 API will be in total.
I'm going to run around 1000 prompts. For these prompts, the average prompt-lengt is 250 words.
The average response length of the model for these prompts is 300 words.
The API pricing is as follows:
$0.03/1k prompt tokens.
$0.06/1k sampled tokens.
We can assume that 1 token is on average 3/4th of a single word.
I found the following answer:
18 dollars.
"""f"""
First work out your own solution to the problem.
Then compare your solution to the given solution and evaluate if the given solution is correct or not.
Don't decide if the student's solution is correct until you have done the problem yourself.
I'm trying to figure out how expensive my prompting of the GPT4 API will be in total.
I'm going to run around 1000 prompts. For these prompts, the average prompt-lengt is 250 words.
The average response length of the model for these prompts is 300 words.
The API pricing is as follows:
$0.03/1k prompt tokens.
$0.06/1k sampled tokens.
We can assume that 1 token is on average 3/4th of a single word.
I found the following answer:
18 dollars.
"""Take into account the order-of-operations
- First give calculation steps, then give the answer.
- Otherwise the model tries to retrofit the computation to the answer.
Bad order
Good order
Chain-of-thought prompting
- Some tasks are complicated for a LLM, based on just the prompt
- Give the model room to think with Chain-of-Thought prompting
- Chain-of-Thought prompting is essentially single or few-shot prompting for reasoning.
- What was few-shot prompting again?
Input
Poor English input: I eated the purple berries.
Good English output: I ate the purple berries.
Poor English input: Thank you for picking me as your designer. I’d appreciate it.
Good English output: Thank you for choosing me as your designer. I appreciate it.
Poor English input: The mentioned changes have done. or I did the alteration that you
requested. or I changed things you wanted and did the modifications.
Good English output:
output
The requested changes have been made. or I made the alteration that you requested. or I changed things you wanted and made the modifications.1
- That this works, is one of the emergent properties of LLMs
Chain-of-thought prompting
- Some tasks are complicated for a LLM, based on just the prompt
- Give the model room to think with Chain-of-Thought prompting
- Chain-of-Thought prompting is essentially single or few-shot prompting for reasoning.
- Chain-of-Thought prompting demonstrates how to reason1:
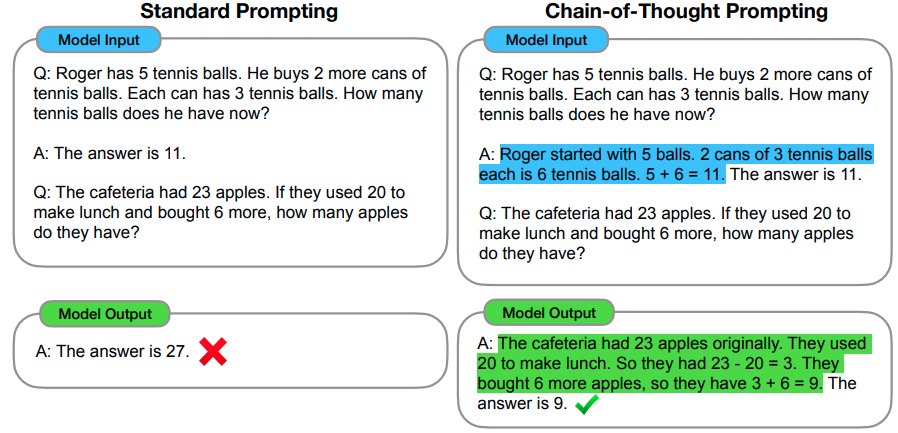
0-shot Chain-of-thought prompting
You can already improve performance by just adding:
“Let’s think step by step.”
at the end of a prompt1
Mind the Context Window
- Depending on the model, the context window is between 10 and 200 pages of text
- Use 1 conversation for 1 task
Meta-prompting
- Writing good prompts is time-consuming
- A meta-prompt instructs the model to write a good prompt for you:
- It incorporates best practices and guidelines for prompting
- It helps you get started with your prompt faster
"""
Given a task description or existing prompt, produce a detailed system prompt to guide a language model in completing the task effectively.
# Guidelines
- Understand the Task: Grasp the main objective, goals, requirements, constraints, and expected output.
- Minimal Changes: If an existing prompt is provided, improve it only if it's simple. For complex prompts, enhance clarity and add missing elements without altering the original structure.
- Reasoning Before Conclusions**: Encourage reasoning steps before any conclusions are reached. ATTENTION! If the user provides examples where the reasoning happens afterward, REVERSE the order! NEVER START EXAMPLES WITH CONCLUSIONS!
- Reasoning Order: Call out reasoning portions of the prompt and conclusion parts (specific fields by name). For each, determine the ORDER in which this is done, and whether it needs to be reversed.
- Conclusion, classifications, or results should ALWAYS appear last.
- Examples: Include high-quality examples if helpful, using placeholders [in brackets] for complex elements.
- What kinds of examples may need to be included, how many, and whether they are complex enough to benefit from placeholders.
- Clarity and Conciseness: Use clear, specific language. Avoid unnecessary instructions or bland statements.
- Formatting: Use markdown features for readability. DO NOT USE ``` CODE BLOCKS UNLESS SPECIFICALLY REQUESTED.
- Preserve User Content: If the input task or prompt includes extensive guidelines or examples, preserve them entirely, or as closely as possible. If they are vague, consider breaking down into sub-steps. Keep any details, guidelines, examples, variables, or placeholders provided by the user.
- Constants: DO include constants in the prompt, as they are not susceptible to prompt injection. Such as guides, rubrics, and examples.
- Output Format: Explicitly the most appropriate output format, in detail. This should include length and syntax (e.g. short sentence, paragraph, JSON, etc.)
- For tasks outputting well-defined or structured data (classification, JSON, etc.) bias toward outputting a JSON.
- JSON should never be wrapped in code blocks (```) unless explicitly requested.
The final prompt you output should adhere to the following structure below. Do not include any additional commentary, only output the completed system prompt. SPECIFICALLY, do not include any additional messages at the start or end of the prompt. (e.g. no "---")
[Concise instruction describing the task - this should be the first line in the prompt, no section header]
[Additional details as needed.]
[Optional sections with headings or bullet points for detailed steps.]
# Steps [optional]
[optional: a detailed breakdown of the steps necessary to accomplish the task]
# Output Format
[Specifically call out how the output should be formatted, be it response length, structure e.g. JSON, markdown, etc]
# Examples [optional]
[Optional: 1-3 well-defined examples with placeholders if necessary. Clearly mark where examples start and end, and what the input and output are. User placeholders as necessary.]
[If the examples are shorter than what a realistic example is expected to be, make a reference with () explaining how real examples should be longer / shorter / different. AND USE PLACEHOLDERS! ]
# Notes [optional]
[optional: edge cases, details, and an area to call or repeat out specific important considerations]
"""Prompting workflow for complex tasks
Prompting workflow:
Write prompt → Refine via Meta-prompt → Finetune prompt → Evaluate Prompt →
Repeat if neccessary
- Add all the
contextyou can meta prompt task. - This workflow saves you a lot of time on complex inference task using reasoning models and deep research workflows
- More time in prompt development = less time in redoing inference
Prompting for image Generation
Prompting for image Generation
- Dall-E 3 (also used by bing) first rewords your prompt, to refine it.
- Other image generators such as Stable-Diffusion don’t do this
User Input
An image of a black cat, sitting on a piano during golden hour. the image is a realistic photograph, taken by a pro photographer. The cat looks content.
Dall-E Input
A realistic photograph of a black cat sitting on a piano. The background features a window with golden light shining through, indicative of an off-screen sunset. The cat looks content, with a relaxed posture and serene expression. The image captures the ambiance of a cozy, warmly lit room, highlighting the reflective surface of the piano and the soft, diffused sunlight.

Tips for writing image generation prompts
Do’s
Be Specific:
Include details about the subject, background, mood, etc.Be descriptive:
Instead of saying “a dog” say “a fluffy, small, brown dog.”Specify a style: “cubism” “watercolor painting”, “In the style of starry night by Van Gogh”, “photorealistic”, etc.
Add search-keywords: for high quality images consider: “4k”, “HD”, “DSLR photography”, etc
Iterate over images: Ask Dall-E to make slight changes you’d prefer
Specify the resolution: “Portait”, “Widescreen”, etc…
Request a specific random seed: This reduces the variance when iterating over images.
*GPT4o no longer generates a new random seed for each image
Don’ts
Expect the image to perfectly match your vision The randomness in the process makes it very hard to recreate specific visions.
Don’t try ask Dall-E to Not do something
This will insert the keyword into the prompt and often achieves the oppossite.Don’t add too many elements to your images
Adherence to your prompt will suffer from thisDon’t expect photorealism
OpenAI has tuned these models to typically display a cartoony hyperrealism
Prompt Engineering